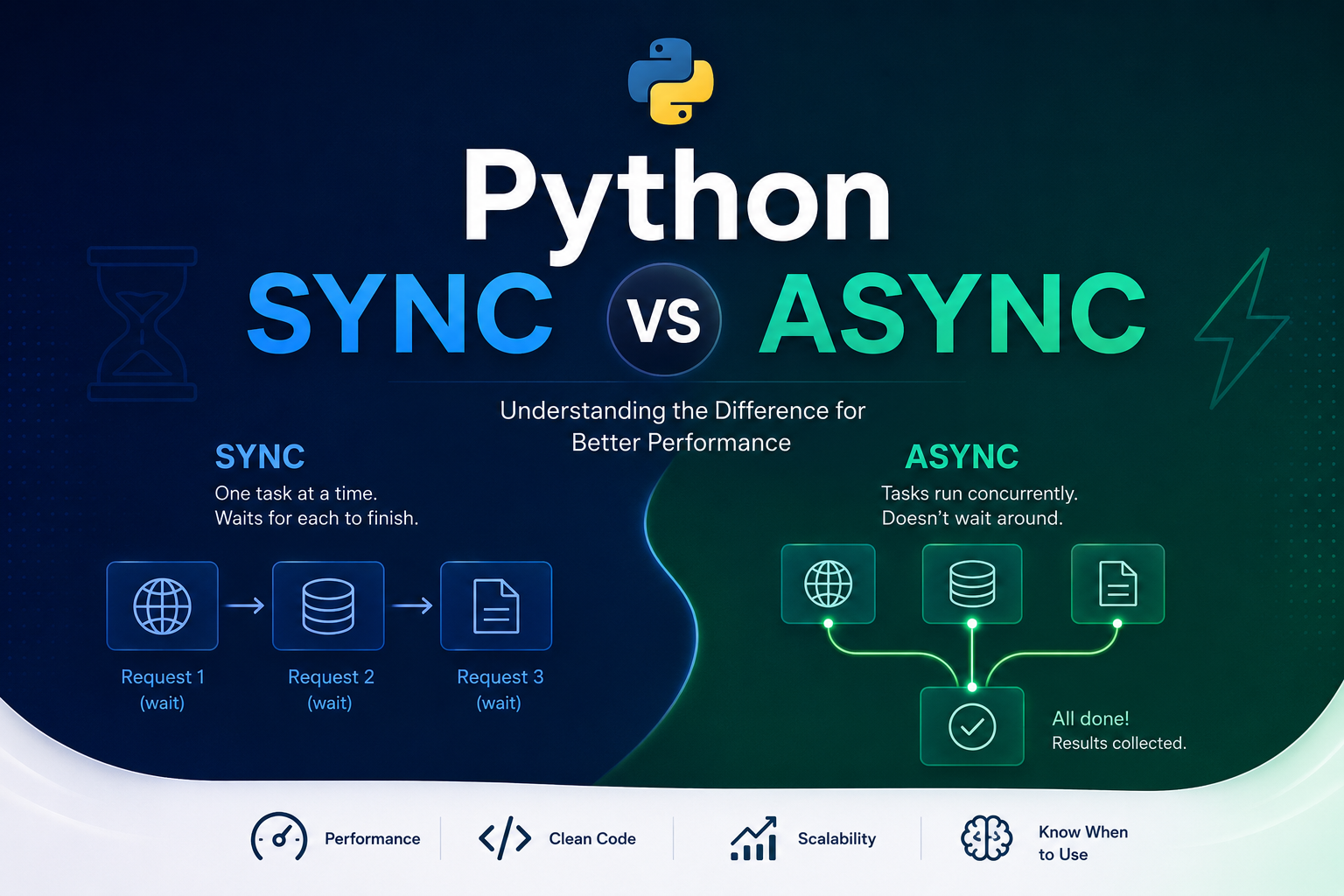
Sync vs Async no Python - Entendendo o que está acontecendo
Quando começamos a programar em Python, quase tudo que escrevemos é síncrono
(modelo de execução onde as operações são realizadas sequencialmente, bloqueando
a thread principal até que cada tarefa seja concluída antes que a próxima seja iniciada).
E isso normalmente funciona muito bem.
Você chama uma função. Ela executa. Depois a próxima executa. E assim por diante.
O problema começa quando a aplicação precisa conversar com o “mundo externo”:
- APIs externas
- Banco de dados
- Upload e download de arquivos
- Redis
- Kafka
- RabbitMQ
- WebSockets
Nesse momento, muitas aplicações começam a ficar lentas, travadas, pouco escaláveis e consumindo recursos desnecessariamente.
É exatamente aqui que entra a programação assíncrona.
Mas antes de sair escrevendo async/await, vale a pena entender o problema que esse modelo resolve - e por que ele existe. Com esse contexto, as peças se encaixam com muito mais naturalidade.
Neste artigo vamos aprender:
- O que um programa faz
- O que é I/O
- O que é CPU e o que significa “bound”
- O que é uma thread e o que é a GIL
- Como funciona o fluxo síncrono
- O que é bloqueio
- O que é async e por que ele existe
- O que é throughput
- Concorrência vs paralelismo
- O que é a biblioteca
asyncio - O que são corrotinas
- O que é o Event Loop
- Como funciona o await
- O que é cooperatividade
- Como tarefas são escalonadas
- O que são Tasks e
asyncio.all_tasks gathervscreate_task- Controle de concorrência: Semaphore vs aiometer
- Sincronização
- O que são Streams
- O que são Timeouts
- Filas assíncronas
requestsehttpx- Rate limit e HTTP 429
- Quando async ajuda e quando não ajuda
O que um programa faz?
Quando um programa executa, ele basicamente está:
- executando instruções
- processando dados
- esperando alguma coisa
- repetindo esse ciclo
Exemplo simples:
print("Olá")O Python lê a instrução, executa, e termina. Rápido, direto, sem espera.
Agora imagine:
response = requests.get("https://api.com")Aqui a situação muda completamente.
O Python agora precisa:
- abrir uma conexão na internet
- encontrar o servidor
- enviar os dados
- esperar a resposta
- receber os dados
- converter a resposta
Tudo isso pode levar milissegundos, segundos ou mais. E durante esse tempo, a aplicação fica parada esperando.
O que é I/O?
Você vai ouvir muito esse termo.
I/O = Input / Output, ou seja: entrada e saída de dados.
Sempre que o programa precisa conversar com algo externo ao processo, temos I/O.
| Operação | Tipo de I/O |
|---|---|
| Chamar API | Rede |
| Ler arquivo | Disco |
| Salvar no banco | Rede/Disco |
| Upload | Rede |
| Download | Rede |
| Kafka | Rede |
| RabbitMQ | Rede |
| Redis | Rede |
A característica mais importante: I/O costuma ser lento. Muito mais lento que a CPU.
O que é CPU? E o que significa “bound”?
CPU é o processador. É quem executa cálculos, e ela é extremamente rápida.
O problema: quando fazemos I/O, a CPU frequentemente fica esperando sem fazer praticamente nada.
CPU: [====]...........[====]...........[====]
trabalha esperando rede trabalha
Todo esse espaço = tempo desperdiçadoO que significa “-bound”?
Você vai ver muito os termos I/O-bound e CPU-bound. Eles descrevem qual recurso é o gargalo da sua aplicação - ou seja, o que está limitando a velocidade.
“Bound” em inglês significa “limitado por” ou “preso em”. Então:
- I/O-bound: a aplicação passa a maior parte do tempo esperando I/O - rede, disco, banco de dados. A CPU está ociosa. O gargalo é a espera.
Aplicação I/O-bound:
CPU: [==].............[==].............[==]
trabalha esperando rede trabalha
↑
80-90% do tempo é espera - CPU ociosa- CPU-bound: a aplicação passa a maior parte do tempo processando - cálculos, renderização, compressão, machine learning. O gargalo é a capacidade de processamento.
Aplicação CPU-bound:
CPU: [=============================================]
processando o tempo inteiro
↑
CPU a 100% - sem tempo ociosoEssa distinção é fundamental para entender quando usar async - e quando ele não ajuda.
O que é uma thread?
Uma thread é um fluxo de execução independente dentro de um processo.
Imagine uma cozinha. Se existe apenas um cozinheiro:
Faz prato 1 → termina → Faz prato 2 → termina → Faz prato 3Isso é parecido com uma única thread: uma coisa por vez, em sequência.
Agora imagine vários cozinheiros trabalhando ao mesmo tempo - teríamos múltiplas threads.
No Python tradicional, normalmente temos uma thread principal executando instruções.
O que é a GIL?
GIL = Global Interpreter Lock
É um mecanismo interno do CPython (a implementação padrão do Python) que garante que apenas uma thread execute bytecode Python por vez, mesmo em máquinas com múltiplos núcleos de CPU.
Sem GIL (ideal teórico): Com GIL (CPython real):
Thread 1: [====][====][====] Thread 1: [====]------[====]
Thread 2: [====][====][====] Thread 2: ------[====]------
Thread 3: [====][====][====] Thread 3: só executa quando as outras liberam
3x mais trabalho praticamente sequencialPor que isso importa?
- Para aplicações I/O-bound: threads funcionam razoavelmente bem, porque enquanto uma thread espera rede ou disco, a GIL é liberada e outra thread pode executar.
- Para aplicações CPU-bound: threads praticamente não ajudam em CPython, porque a GIL impede execução paralela real. Nesse caso, a solução é
multiprocessing- processos separados têm GILs separadas.
A GIL é também uma das razões pelas quais async com uma única thread pode ser mais eficiente do que múltiplas threads para I/O: sem overhead de troca de contexto, sem disputa por lock.
Como funciona o fluxo síncrono?
No modelo síncrono, uma tarefa precisa terminar antes da próxima começar.
import requests
response1 = requests.get("https://api.com/1")
response2 = requests.get("https://api.com/2")
response3 = requests.get("https://api.com/3")Fluxo visual - o tempo passa da esquerda para a direita:
Tempo →→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→
Request 1: [envia][========esperando========][recebe]
Request 2: [envia][========esperando========][recebe]
Request 3: [envia][========esperando========][recebe]Enquanto o Request 1 espera resposta, o Request 2 sequer começa. Tudo em fila, um por vez.
O problema do modelo síncrono
Imagine: cada request demora 500ms. Temos 100 requests.
100 × 500ms = 50 segundos de esperaMas existe um detalhe importante. Durante grande parte desses 500ms, a CPU não está trabalhando - ela está esperando a rede responder. É tempo puro de desperdício.
O que é bloqueio?
Bloqueio acontece quando uma operação impede o programa de continuar enquanto não termina.
requests.get(url) # ← operação bloqueanteEnquanto a resposta não chega:
- a thread fica parada
- o código não avança
- nada mais pode acontecer naquela execução
Isso é chamado de operação bloqueante. O problema não é o processamento - é o tempo desperdiçado esperando. E é exatamente isso que o async resolve.
O que é async?
Async é um modelo de programação focado em concorrência durante espera de I/O.
Async não significa:
- “rodar tudo ao mesmo tempo”
- “usar vários núcleos da CPU”
- “ficar mais rápido em qualquer situação”
O objetivo é simples: aproveitar o tempo em que o programa estaria parado esperando.
A ideia principal do async
Ao invés de:
Executa → Espera parado → Executa → Espera paradoTemos:
Executa → Espera sem bloquear → Enquanto espera, outra tarefa executaVisualmente com timeline:
Tempo →→→→→→→→→→→→→→→→→→→→→→→→→→→→→
Request 1: [envia][=====esperando=====][recebe]
Request 2: [envia][========esperando========][recebe]
Request 3: [envia][===esperando===][recebe]
↑
todos começam quase ao mesmo tempo
o Event Loop alterna entre eles enquanto esperamEm vez de esperar um terminar para começar o próximo, o async inicia todos e vai alternando conforme cada um recebe resposta.
O que é throughput?
Throughput é a quantidade de trabalho realizado em determinado período de tempo.
Exemplo: uma API que consegue processar 100 requests por segundo tem maior throughput do que uma que processa 10 por segundo.
Async normalmente melhora throughput em operações de I/O porque a aplicação para menos tempo parada esperando.
Concorrência vs paralelismo - a diferença que importa
Esses dois termos são frequentemente confundidos. Entender a diferença é essencial.
Concorrência: várias tarefas progredindo juntas, alternando execução em uma única thread.
Paralelismo: várias tarefas executando literalmente ao mesmo tempo, em múltiplos núcleos/processos.
CONCORRÊNCIA (async - 1 thread, 3 tarefas):
Thread única: [A][B][A][C][B][A termina][C][B termina][C termina]
↑
uma de cada vez, mas todas progridem
A fica na fila enquanto B executa, e vice-versa
PARALELISMO (multiprocessing - 3 processos):
Processo 1: [A executa===================]
Processo 2: [B executa===================]
Processo 3: [C executa===================]
↑
realmente simultâneas, em núcleos diferentesAsync usa concorrência, não paralelismo. Para paralelismo real em CPU-bound, você precisa de multiprocessing.
O que é a biblioteca `asyncio`?
Antes de entrar em async, await, sleep, gather e todo o resto, vale entender de onde vêm essas funções - e o que é a biblioteca que as fornece.
asyncio é uma biblioteca da biblioteca padrão do Python (não precisa instalar nada). Ela foi introduzida oficialmente no Python 3.4 e se tornou a base do modelo assíncrono moderno da linguagem.
Ela resolve um problema específico: como escrever código que pode esperar operações de I/O sem travar o programa?
Para isso, o asyncio fornece toda a infraestrutura necessária:
| O que fornece | Para que serve |
|---|---|
asyncio.run() | Inicia o Event Loop e executa uma corrotina principal |
asyncio.sleep() | Espera sem bloquear (diferente de time.sleep) |
asyncio.create_task() | Agenda uma corrotina no Event Loop como Task |
asyncio.gather() | Executa várias corrotinas concorrentemente |
asyncio.all_tasks() | Retorna todas as Tasks ativas no Event Loop |
asyncio.Queue | Fila assíncrona para comunicação entre corrotinas |
asyncio.Lock | Garante acesso exclusivo a recursos compartilhados |
asyncio.Semaphore | Limita quantas corrotinas acessam algo simultaneamente |
asyncio.Event | Sinaliza que algo aconteceu para outras corrotinas |
Quando você importa asyncio:
import asyncioVocê está trazendo essa infraestrutura inteira para o seu código.
As palavras async e await em si fazem parte da sintaxe do Python (não são funções do asyncio). Mas elas só funcionam dentro de um Event Loop - e quem fornece e gerencia esse Event Loop é o asyncio.
Entendendo isso, fica fácil saber de onde vem cada coisa: asyncio.run() inicia tudo, async def define uma corrotina, await pausa e entrega controle, e as funções do asyncio cuidam do resto.
O que é async e await?
Essas duas palavras são a base da programação assíncrona moderna em Python.
async
Quando escrevemos:
async def buscar_dados():
passEstamos dizendo ao Python: “essa função é assíncrona”. Ela se torna uma corrotina.
O que é uma corrotina?
Uma corrotina é uma função especial que pode pausar no meio da execução, entregar o controle para outra tarefa, e continuar de onde parou quando for retomada.
Comparando com uma função normal:
Função normal: Corrotina:
Começa Começa
↓ ↓
Executa tudo de uma vez Executa um trecho
↓ ↓
Termina Encontra await → pausa
↓
Outra tarefa executa
↓
I/O responde → retoma daqui
↓
Continua executando
↓
TerminaEssa capacidade de pausar e retomar é a essência do async.
await
O await é a palavra que faz a pausa acontecer.
await asyncio.sleep(2)Isso não significa apenas “esperar 2 segundos”. Significa:
“Estou esperando. Pode executar outra tarefa enquanto isso.”
Esse detalhe muda tudo. É a diferença entre travar o sistema e aproveitar o tempo ocioso.
Sem await - o erro clássico
Se não existe await, a corrotina não entrega controle. E vai bloquear o sistema da mesma forma que código síncrono.
import asyncio
import time
async def tarefa_errada():
print("Iniciou")
time.sleep(5) # ← ERRADO: bloqueia o Event Loop inteiro
print("Terminou")
async def outra_tarefa():
print("Outra tarefa rodando")
async def main():
task1 = asyncio.create_task(tarefa_errada())
task2 = asyncio.create_task(outra_tarefa())
await task1
await task2
asyncio.run(main())
# Saída:
# Iniciou
# (5 segundos de silêncio - outra_tarefa não executa durante esse tempo)
# Terminou
# Outra tarefa rodandoO correto:
import asyncio
async def tarefa_correta():
print("Iniciou")
await asyncio.sleep(5) # ← libera o Event Loop
print("Terminou")
async def outra_tarefa():
print("Outra tarefa rodando")
async def main():
task1 = asyncio.create_task(tarefa_correta())
task2 = asyncio.create_task(outra_tarefa())
await task1
await task2
asyncio.run(main())
# Saída:
# Iniciou
# Outra tarefa rodando ← executa durante o sleep!
# TerminouO que é o Event Loop?
O Event Loop é o coração do async. É ele quem gerencia todas as corrotinas e decide qual executa a cada momento.
Pense nele como um coordenador de mesa redonda: ele pergunta a cada tarefa “você está pronta para continuar?”, executa as que estão, e coloca de volta na fila as que estão esperando.
Ciclo de funcionamento:
┌──────────────────────────────────────────────────┐
│ EVENT LOOP │
│ │
│ 1. Pega a próxima task pronta na fila │
│ ↓ │
│ 2. Executa até encontrar um await │
│ ↓ │
│ 3. Task pausa, entrega controle ao Event Loop │
│ ↓ │
│ 4. Event Loop pega a próxima task pronta │
│ ↓ │
│ 5. Quando I/O responde, reagenda a task │
│ ↓ │
│ 6. Volta ao passo 1 │
└──────────────────────────────────────────────────┘Gerenciando múltiplas tarefas ao mesmo tempo:
Event Loop
|
┌──────────────┼──────────────┐
│ │ │
Tarefa A Tarefa B Tarefa C
│ │ │
esperando API esperando DB esperando arquivo
│ │ │
(volta quando (volta quando (volta quando
API responder) DB responder) leitura terminar)Quando uma tarefa faz await, o Event Loop imediatamente passa para a próxima disponível. Nenhum tempo é desperdiçado esperando.
O que é cooperatividade?
O modelo async funciona de maneira cooperativa.
Cada corrotina precisa voluntariamente ceder o controle usando await. Quando faz isso, ela diz ao Event Loop: “pode executar outra tarefa agora, eu estou esperando”.
COM cooperatividade:
Tarefa A: [executa]→await→[executa]→await→[termina]
Tarefa B: [executa]→await→[executa]→[termina]
Tarefa C: [executa]→[termina]
↑
Event Loop alterna entre elas nos pontos de await
SEM cooperatividade (tarefa A nunca usa await):
Tarefa A: [executa...executa...executa...executa...termina]
Tarefa B: [executa] ← só começa depois
Tarefa C: [executa] ← idem
↑
Event Loop fica preso em A o tempo todoIsso é diferente de threads, onde o sistema operacional pode forçar a troca de contexto. No async, a tarefa precisa cooperar.
O que são tasks?
Tasks são corrotinas que foram entregues ao Event Loop para gerenciar.
Uma corrotina sozinha é apenas um objeto - ela não executa até você fazer await. Quando você cria uma Task, o Event Loop assume o controle e começa a executar aquela corrotina em background.
corrotina = buscar(url) # objeto, ainda não executa
task = asyncio.create_task(buscar(url)) # agendada, começa a executar agoraVisualmente:
Corrotina (objeto Python)
↓
asyncio.create_task()
↓
Task criada e agendada no Event Loop
↓
Event Loop começa a executar quando possível
↓
Você pode continuar fazendo outras coisas e fazer await na Task depoisExemplo completo de tasks
import asyncio
async def buscar_dado(nome, segundos):
"""Simula uma busca que leva 'segundos' para responder."""
print(f"[{nome}] Iniciando busca...")
await asyncio.sleep(segundos)
print(f"[{nome}] Busca concluída após {segundos}s")
return f"resultado de {nome}"
async def main():
print("Criando tasks...")
# create_task agenda as corrotinas imediatamente
task1 = asyncio.create_task(buscar_dado("API de usuários", 2))
task2 = asyncio.create_task(buscar_dado("API de produtos", 1))
task3 = asyncio.create_task(buscar_dado("API de pedidos", 3))
print("Tasks criadas. Aguardando resultados...")
# await nas tasks: espera cada uma terminar
resultado1 = await task1
resultado2 = await task2
resultado3 = await task3
print(f"\nResultados: {resultado1}, {resultado2}, {resultado3}")
asyncio.run(main())
# Saída:
# Criando tasks...
# Tasks criadas. Aguardando resultados...
# [API de usuários] Iniciando busca...
# [API de produtos] Iniciando busca...
# [API de pedidos] Iniciando busca...
# [API de produtos] Busca concluída após 1s ← termina primeiro
# [API de usuários] Busca concluída após 2s
# [API de pedidos] Busca concluída após 3s ← termina por último
# Tempo total: ~3s (não 6s, porque rodaram concorrentemente)O que é `asyncio.all_tasks`?
O asyncio.all_tasks() retorna o conjunto de todas as Tasks que estão atualmente ativas no Event Loop.
É muito útil para:
- monitorar quantas tasks estão rodando
- depurar situações onde tasks ficam presas ou não terminam
- cancelar tasks em shutdown da aplicação
- inspecionar o estado do sistema em tempo de execução
asyncio.all_tasks()
# retorna: Set[Task] - todas as tasks ativas no momentoExemplo completo: monitorando tasks em execução
import asyncio
async def tarefa_lenta(nome, segundos):
print(f"[{nome}] iniciou")
await asyncio.sleep(segundos)
print(f"[{nome}] terminou")
async def monitor():
"""Verifica quantas tasks estão ativas a cada segundo."""
for _ in range(4):
await asyncio.sleep(1)
tasks_ativas = asyncio.all_tasks()
# filtra a própria task do monitor para não contar ela mesma
tasks_de_trabalho = {t for t in tasks_ativas if t.get_name() != "monitor"}
print(f"[monitor] Tasks ativas: {len(tasks_de_trabalho)}")
for t in tasks_de_trabalho:
print(f" - {t.get_name()}: {'executando' if not t.done() else 'concluída'}")
async def main():
# cria tasks com nomes para facilitar a leitura
task1 = asyncio.create_task(tarefa_lenta("busca-A", 2), name="busca-A")
task2 = asyncio.create_task(tarefa_lenta("busca-B", 3), name="busca-B")
task3 = asyncio.create_task(tarefa_lenta("busca-C", 1), name="busca-C")
mon = asyncio.create_task(monitor(), name="monitor")
await asyncio.gather(task1, task2, task3, mon)
asyncio.run(main())
# Saída aproximada:
# [busca-A] iniciou
# [busca-B] iniciou
# [busca-C] iniciou
# [busca-C] terminou ← termina em 1s
# [monitor] Tasks ativas: 2
# - busca-A: executando
# - busca-B: executando
# [busca-A] terminou ← termina em 2s
# [monitor] Tasks ativas: 1
# - busca-B: executando
# [busca-B] terminou ← termina em 3s
# [monitor] Tasks ativas: 0Exemplo: cancelando todas as tasks no shutdown
Um uso muito comum em produção é cancelar todas as tasks pendentes ao encerrar a aplicação:
import asyncio
import signal
async def worker(nome):
try:
print(f"[{nome}] trabalhando...")
await asyncio.sleep(60) # simula trabalho longo
print(f"[{nome}] concluído")
except asyncio.CancelledError:
print(f"[{nome}] foi cancelada durante shutdown")
raise # importante: re-raise para o Event Loop saber que foi cancelada
async def main():
tasks = [
asyncio.create_task(worker("task-1")),
asyncio.create_task(worker("task-2")),
asyncio.create_task(worker("task-3")),
]
# simula um sinal de shutdown após 2 segundos
await asyncio.sleep(2)
print("\nIniciando shutdown...")
# cancela todas as tasks ativas (exceto a própria main)
todas = asyncio.all_tasks()
task_atual = asyncio.current_task()
para_cancelar = todas - {task_atual}
for task in para_cancelar:
task.cancel()
# aguarda todas terminarem (seja concluindo ou sendo canceladas)
await asyncio.gather(*para_cancelar, return_exceptions=True)
print("Shutdown completo.")
asyncio.run(main())
# Saída:
# [task-1] trabalhando...
# [task-2] trabalhando...
# [task-3] trabalhando...
#
# Iniciando shutdown...
# [task-1] foi cancelada durante shutdown
# [task-2] foi cancelada durante shutdown
# [task-3] foi cancelada durante shutdown
# Shutdown completo.gather vs create_task - qual usar?
Esses dois são frequentemente usados juntos, mas têm papéis distintos.
asyncio.create_task
Agenda uma corrotina individualmente no Event Loop. Você recebe um objeto Task que pode controlar - cancelar, verificar se terminou, pegar o resultado.
task1 = asyncio.create_task(buscar("A"))
task2 = asyncio.create_task(buscar("B"))
# ambas já estão rodando em background aqui
# você pode fazer outras coisas...
resultado1 = await task1 # espera task1 especificamente
resultado2 = await task2asyncio.gather
Recebe múltiplas corrotinas (ou tasks) e espera todas terminarem, retornando os resultados na mesma ordem em que foram passadas.
resultado1, resultado2, resultado3 = await asyncio.gather(
buscar("A"),
buscar("B"),
buscar("C"),
)Exemplo completo comparando os dois
import asyncio
import time
async def buscar(nome, segundos):
await asyncio.sleep(segundos)
return f"dado de {nome}"
async def com_create_task():
inicio = time.perf_counter()
task1 = asyncio.create_task(buscar("API-1", 2))
task2 = asyncio.create_task(buscar("API-2", 1))
# posso fazer outra coisa enquanto as tasks rodam
print("Tasks criadas, fazendo outra coisa...")
await asyncio.sleep(0.1)
print("Terminei outra coisa, aguardando tasks...")
r1 = await task1
r2 = await task2
print(f"create_task: {r1}, {r2} em {time.perf_counter() - inicio:.1f}s")
async def com_gather():
inicio = time.perf_counter()
r1, r2 = await asyncio.gather(
buscar("API-1", 2),
buscar("API-2", 1),
)
print(f"gather: {r1}, {r2} em {time.perf_counter() - inicio:.1f}s")
asyncio.run(com_create_task())
asyncio.run(com_gather())
# Saída:
# Tasks criadas, fazendo outra coisa...
# Terminei outra coisa, aguardando tasks...
# create_task: dado de API-1, dado de API-2 em 2.0s
# gather: dado de API-1, dado de API-2 em 2.0sAmbos levam ~2s (limitados pela task mais lenta). A diferença é no controle.
Quando usar cada um?
| Situação | Use |
|---|---|
| Quer os resultados de N corrotinas de uma vez | gather |
| Quer iniciar uma task em background e continuar | create_task |
| Precisa cancelar tasks individualmente | create_task (tem .cancel()) |
| Quer que uma falha não cancele as outras | gather(return_exceptions=True) |
Como tarefas são escalonadas?
Escalonamento é o processo do Event Loop decidir qual task executa a seguir.
O asyncio usa um escalonador cooperativo e baseado em fila de callbacks:
- Quando uma task faz
awaitem uma operação de I/O, ela registra um callback (“me avise quando terminar”) e sai da fila de execução. - O Event Loop pega a próxima task pronta.
- Quando o I/O responde, o callback é chamado e a task volta para a fila de prontos.
- O Event Loop a executa na próxima iteração.
Fila de prontos: [main] [task_A] [task_B]
↓
Event Loop executa main
main faz await → registra callback → sai da fila
↓
Fila de prontos: [task_A] [task_B]
Event Loop executa task_A
task_A faz await I/O → registra callback → sai
↓
Fila de prontos: [task_B]
Event Loop executa task_B
...
↓
I/O de main responde → main volta para fila
Fila de prontos: [main]
Event Loop executa main de onde parouNão há prioridade entre tasks por padrão. O escalonamento é FIFO (primeiro a entrar, primeiro a sair) para tasks prontas.
Controle de concorrência
Um erro muito comum ao aprender async: criar tarefas demais de uma vez.
# isso pode explodir
tarefas = [buscar(url) for url in urls_gigante]
await asyncio.gather(*tarefas) # 100 mil requests ao mesmo tempo!Isso pode causar:
- rate limit na API externa
- explosão de memória (cada task ocupa RAM)
- sobrecarga no servidor destino
- banimento de IP
A solução é controlar a concorrência. Temos duas ferramentas principais para isso: asyncio.Semaphore e aiometer. Elas resolvem o mesmo problema, mas de formas diferentes.
O que é um Semaphore?
Um Semaphore (semáforo) é uma primitiva de sincronização que controla quantas corrotinas podem estar executando uma seção de código ao mesmo tempo.
Pense como uma fila de catraca com N vagas. Quando todas as vagas estão ocupadas, quem chegar precisa esperar alguém sair.
Semaphore(3) - máximo 3 simultâneas:
Task 1: →→ entra [========] sai →
Task 2: →→ entra [============] sai →
Task 3: →→ entra [======] sai →
Task 4: .....(espera vaga)→→ entra [========] sai →
Task 5: .........(espera vaga)→→ entra [======] sai →
↑
máximo 3 dentro ao mesmo tempoExemplo completo com Semaphore
import asyncio
import time
import httpx
# limita a 5 requests simultâneas
semaphore = asyncio.Semaphore(5)
async def buscar(client, url, numero):
async with semaphore: # ← tenta entrar; se já tem 5 dentro, espera
print(f" [req {numero:3d}] iniciando")
response = await client.get(url)
data = response.json()
print(f" [req {numero:3d}] concluída - título: {data.get('title', '')[:30]}")
return data
async def main():
urls = [
(f"https://jsonplaceholder.typicode.com/posts/{i}", i)
for i in range(1, 21) # 20 URLs
]
inicio = time.perf_counter()
async with httpx.AsyncClient() as client:
tarefas = [buscar(client, url, num) for url, num in urls]
resultados = await asyncio.gather(*tarefas)
fim = time.perf_counter()
print(f"\nTotal: {len(resultados)} resultados em {fim - inicio:.2f}s")
print("Máximo simultâneo foi 5 (controlado pelo Semaphore)")
asyncio.run(main())O Semaphore controla quantas entram ao mesmo tempo, mas não controla a taxa por segundo (quantas por minuto/segundo). Isso é importante: 5 simultâneas podem terminar todas em 0.1s e você já tem 5 novas começando.
O que é aiometer?
O aiometer é uma biblioteca que resolve o controle de concorrência de forma mais completa.
Ele permite controlar duas dimensões ao mesmo tempo:
max_at_once: quantas tasks simultâneas no máximomax_per_second: quantas tasks por segundo no máximo
Semaphore vs aiometer - qual a diferença real?
| Aspecto | asyncio.Semaphore | aiometer |
|---|---|---|
| Limita simultâneas | ✅ sim | ✅ sim (max_at_once) |
| Limita por segundo (rate) | ❌ não | ✅ sim (max_per_second) |
| Nativo do Python | ✅ sim | ❌ instalar com pip |
| Verbosidade | mais código manual | mais conciso |
| Caso de uso | controle simples | produção com APIs externas |
Quando usar cada um:
Use Semaphore quando você só precisa limitar concorrência e não se importa com a taxa por segundo - por exemplo, consultas ao seu próprio banco de dados.
Use aiometer quando estiver chamando APIs externas que possuem rate limit (ex.: “máximo 60 requests por minuto”). O Semaphore sozinho não consegue garantir isso, porque 60 tasks simultâneas podem todas terminar em 1 segundo e você já ultrapassou o limite.
Exemplo completo com aiometer
import asyncio
import time
import aiometer
import httpx
async def buscar(client, url, numero):
response = await client.get(url)
data = response.json()
print(f" [req {numero:3d}] título: {data.get('title', '')[:40]}")
return data
async def main():
urls = [
(f"https://jsonplaceholder.typicode.com/posts/{i}", i)
for i in range(1, 21)
]
inicio = time.perf_counter()
async with httpx.AsyncClient() as client:
resultados = await aiometer.run_all(
[lambda u=url, n=num: buscar(client, u, n) for url, num in urls],
max_at_once=5, # máximo 5 simultâneas
max_per_second=3, # máximo 3 por segundo
)
fim = time.perf_counter()
print(f"\nTotal: {len(resultados)} resultados em {fim - inicio:.2f}s")
print("Respeitou: máx 5 simultâneas E máx 3/segundo")
asyncio.run(main())Com max_per_second=3 e 20 URLs, o aiometer vai levar pelo menos ~6.7s (20 / 3 = 6.7s) independentemente de quantas simultâneas você permite. Ele espaça as requisições no tempo.
O que são timeouts?
Timeout é o tempo máximo de espera por uma operação. Se a operação não terminar dentro do prazo, um erro é lançado.
Sem timeout, uma aplicação pode ficar presa esperando eternamente - por exemplo, se o servidor travar ou a rede cair no meio da requisição.
Exemplo completo com timeout no httpx
import asyncio
import httpx
async def buscar_com_timeout(url: str, timeout_segundos: float):
try:
async with httpx.AsyncClient() as client:
response = await client.get(url, timeout=timeout_segundos)
return response.json()
except httpx.TimeoutException:
print(f"Timeout após {timeout_segundos}s para: {url}")
return None
except httpx.RequestError as e:
print(f"Erro de conexão: {e}")
return None
async def main():
urls = [
"https://jsonplaceholder.typicode.com/posts/1", # rápida
"https://httpbin.org/delay/10", # demora 10s - vai dar timeout
]
for url in urls:
print(f"Buscando: {url}")
resultado = await buscar_com_timeout(url, timeout_segundos=3.0)
if resultado:
print(f"Sucesso: {str(resultado)[:60]}...")
print()
asyncio.run(main())
# Saída:
# Buscando: https://jsonplaceholder.typicode.com/posts/1
# Sucesso: {'userId': 1, 'id': 1, 'title': 'sunt aut facere repell...
#
# Buscando: https://httpbin.org/delay/10
# Timeout após 3.0s para: https://httpbin.org/delay/10O que são streams?
Streams são fluxos contínuos de dados. Ao invés de esperar o dado completo chegar e carregar tudo na memória de uma vez, os dados chegam em partes (chunks) conforme ficam disponíveis.
Quando isso é útil:
- download de arquivo grande
- vídeo ou áudio em tempo real
- logs sendo gerados continuamente
- WebSockets
- respostas de LLMs (tokens chegando um a um)
No async, streams funcionam muito bem porque o Event Loop consegue processar cada chunk conforme chega, sem bloquear.
Exemplo completo: download com stream
import asyncio
import httpx
async def download_com_progresso(url: str, destino: str):
"""Baixa um arquivo exibindo o progresso chunk a chunk."""
async with httpx.AsyncClient() as client:
async with client.stream("GET", url) as response:
total = int(response.headers.get("content-length", 0))
baixado = 0
with open(destino, "wb") as arquivo:
async for chunk in response.aiter_bytes(chunk_size=8192):
arquivo.write(chunk)
baixado += len(chunk)
if total:
pct = (baixado / total) * 100
print(f"\r Progresso: {pct:.1f}% ({baixado}/{total} bytes)", end="")
print(f"\nDownload concluído: {destino}")
async def main():
# arquivo de exemplo público (~1MB)
url = "https://httpbin.org/bytes/102400"
await download_com_progresso(url, "/tmp/arquivo_baixado.bin")
asyncio.run(main())O async for chunk in response.aiter_bytes() itera sobre os pedaços conforme chegam. Se usássemos response.read() (sem stream), esperaríamos tudo chegar para só então processar - problema grave com arquivos grandes.
O que são filas assíncronas?
Filas permitem comunicação ordenada entre corrotinas - uma produz dados, outra consome - sem que elas precisem se conhecer diretamente.
Produtor: gera itens e coloca na fila
↓
asyncio.Queue
↓
Consumidor: pega itens da fila e processaIsso é útil para separar a velocidade de produção da velocidade de consumo, e para pipelines de processamento.
Exemplo completo: produtor e consumidor
import asyncio
import random
async def produtor(fila: asyncio.Queue, quantidade: int):
"""Gera itens e coloca na fila."""
for i in range(quantidade):
item = f"item-{i+1}"
await fila.put(item)
print(f"[produtor] colocou: {item} (fila tem {fila.qsize()} itens)")
await asyncio.sleep(random.uniform(0.1, 0.4)) # simula tempo de geração
# sinaliza fim com valor sentinela
await fila.put(None)
print("[produtor] encerrou")
async def consumidor(fila: asyncio.Queue):
"""Consome itens da fila até receber None."""
while True:
item = await fila.get() # espera sem bloquear até ter item
if item is None:
print("[consumidor] recebeu sinal de fim")
break
print(f"[consumidor] processando: {item}")
await asyncio.sleep(random.uniform(0.2, 0.5)) # simula processamento
fila.task_done()
async def main():
fila = asyncio.Queue(maxsize=3) # máximo 3 itens na fila ao mesmo tempo
prod = asyncio.create_task(produtor(fila, quantidade=8))
cons = asyncio.create_task(consumidor(fila))
await asyncio.gather(prod, cons)
print("Pipeline concluído.")
asyncio.run(main())O maxsize=3 faz o produtor pausar quando a fila está cheia - ele só continua quando o consumidor retirar um item. Isso é backpressure: evita que o produtor sobrecarregue o consumidor.
O que é sincronização?
Mesmo no async, várias corrotinas podem acessar recursos compartilhados: uma lista, um arquivo, um contador, um cache.
Quando isso acontece sem controle, podemos ter:
- race condition: duas corrotinas leem o mesmo valor, incrementam, e uma sobrescreve a outra
- corrupção de dados: estado inconsistente
- resultados incorretos sem erro visível (o pior tipo de bug)
Ferramentas de sincronização do asyncio
| Ferramenta | Para que serve |
|---|---|
asyncio.Lock | Acesso exclusivo: só uma corrotina por vez |
asyncio.Semaphore | Acesso limitado: N corrotinas por vez |
asyncio.Event | Sinaliza que algo aconteceu |
asyncio.Queue | Comunicação ordenada entre corrotinas |
Exemplo completo: race condition e como corrigir com Lock
import asyncio
# VERSÃO COM RACE CONDITION
contador_sem_lock = 0
async def incrementar_sem_lock():
global contador_sem_lock
valor = contador_sem_lock
await asyncio.sleep(0) # simula uma pausa (permite troca de contexto)
contador_sem_lock = valor + 1
# VERSÃO CORRETA COM LOCK
contador_com_lock = 0
lock = asyncio.Lock()
async def incrementar_com_lock():
global contador_com_lock
async with lock:
valor = contador_com_lock
await asyncio.sleep(0) # mesmo com pausa, o lock garante exclusividade
contador_com_lock = valor + 1
async def main():
n = 100 # 100 corrotinas incrementando ao mesmo tempo
# sem lock: race condition
tarefas = [incrementar_sem_lock() for _ in range(n)]
await asyncio.gather(*tarefas)
print(f"Sem lock: esperado={n}, obtido={contador_sem_lock}")
# Exemplo de saída: Sem lock: esperado=100, obtido=1 ← errado!
# com lock: correto
tarefas = [incrementar_com_lock() for _ in range(n)]
await asyncio.gather(*tarefas)
print(f"Com lock: esperado={n}, obtido={contador_com_lock}")
# Saída: Com lock: esperado=100, obtido=100 ← correto
asyncio.run(main())Exemplo real: Sync vs Async
Vamos comparar os dois modelos com código que você pode executar agora mesmo.
Usaremos a API pública https://jsonplaceholder.typicode.com - gratuita, sem autenticação.
Versão síncrona
import time
import requests
def buscar_sync(url):
response = requests.get(url)
return response.json()
def main():
urls = [
f"https://jsonplaceholder.typicode.com/posts/{i}"
for i in range(1, 101) # 100 URLs
]
inicio = time.perf_counter()
resultados = []
for url in urls:
dado = buscar_sync(url)
resultados.append(dado)
fim = time.perf_counter()
print(f"Total de resultados: {len(resultados)}")
print(f"Tempo total: {fim - inicio:.2f}s")
main()O que está acontecendo?
para cada URL:
requests.get(url) ← bloqueia aqui
(nenhum outro código executa enquanto espera)Fluxo visual:
Tempo →→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→
URL 1: [==esperando==]
URL 2: [==esperando==]
URL 3: [==esperando==]
...
URL 100: ... [==esperando==]Resultado: as 100 URLs são buscadas uma por vez, em sequência.
Sobre o tempo de execução
O tempo real depende de vários fatores que estão fora do seu controle:
- latência de rede entre você e o servidor (distância física, roteamento)
- carga atual do servidor público (pode estar recebendo muitas requisições)
- velocidade da sua conexão com a internet
- DNS e handshake TCP/TLS (a primeira requisição costuma ser mais lenta)
- throttling do seu provedor de internet
Por isso, o tempo varia a cada execução. Medições reais reportadas: 15s, 30s, 58s para 100 URLs síncronas. O ponto importante não é o número exato - é que todo esse tempo é espera pura, não trabalho.
Versão assíncrona
import asyncio
import time
import httpx
async def buscar_async(client: httpx.AsyncClient, url: str):
response = await client.get(url)
return response.json()
async def main():
urls = [
f"https://jsonplaceholder.typicode.com/posts/{i}"
for i in range(1, 101) # 100 URLs
]
inicio = time.perf_counter()
async with httpx.AsyncClient() as client:
tarefas = [buscar_async(client, url) for url in urls]
resultados = await asyncio.gather(*tarefas)
fim = time.perf_counter()
print(f"Total de resultados: {len(resultados)}")
print(f"Tempo total: {fim - inicio:.2f}s")
asyncio.run(main())O que está acontecendo?
tarefas = [buscar_async(client, url) for url in urls]Cria 100 corrotinas. Nesse ponto elas ainda não executaram.
await asyncio.gather(*tarefas)Agenda todas as 100 no Event Loop e espera todas terminarem.
Fluxo visual:
Tempo →→→→→→→→→→→→→→→→
URL 1: [envia][=====esperando=====][recebe]
URL 2: [envia][========esperando========][recebe]
URL 3: [envia][===esperando===][recebe]
...
URL 100: [envia][======esperando======][recebe]
↑
todas iniciam quase ao mesmo tempo
Event Loop alterna entre elas conforme esperamEnquanto URL 1 espera resposta, URLs 2, 3, 4… estão todas esperando também - o Event Loop aproveita cada momento em que alguma está esperando para avançar as outras.
Resultado: ~1s para 100 URLs (medição real: 1.04s).
A diferença de tempo não é coincidência - ela representa o quanto de tempo era puro desperdício na versão síncrona.
Por que async NÃO é melhor em tudo?
Muita gente acha que async deixa qualquer código mais rápido. Isso não é verdade.
Precisamos entender dois tipos de problema:
I/O-Bound
Aplicações limitadas por espera de I/O - APIs, banco de dados, rede, uploads, downloads, streams.
CPU: [10% trabalhando][ 90% esperando I/O ]
Async: [outras tarefas aqui →→→]
↑
aproveita os 90% que seriam desperdiçadosAsync ajuda muito aqui.
CPU-Bound
Aplicações limitadas por processamento pesado da CPU - machine learning, renderização, compressão, criptografia, processamento matemático.
CPU: [100% trabalhando=====================================]
Async: não há tempo ocioso para aproveitarA CPU está ocupada o tempo inteiro. Async não resolve - e ainda adiciona overhead desnecessário.
O que usar em CPU-bound?
Multiprocessing
Usa múltiplos processos, cada um com sua própria GIL. Aproveita múltiplos núcleos da CPU em paralelo real.
from multiprocessing import Pool
def calcular_pesado(n):
"""Simula processamento intensivo de CPU."""
return sum(i * i for i in range(n))
if __name__ == "__main__":
dados = [10_000_000, 20_000_000, 15_000_000, 5_000_000]
with Pool(processes=4) as pool:
resultados = pool.map(calcular_pesado, dados)
print(resultados)Threads
Podem ajudar em I/O e tarefas leves, mas lembre-se da GIL: para CPU-bound em CPython, threads não oferecem paralelismo real.
Workers
Workers são processos separados processando tarefas de uma fila. Muito usados com Celery + RabbitMQ ou Kafka para processamento distribuído.
Nota: multiprocessing, threads e workers são temas com profundidade própria e merecem artigos separados. Aqui servem apenas como contexto para mostrar que async não é a solução universal.
Quando vale a pena usar async?
Async faz muito sentido quando existem muitas conexões simultâneas, espera de rede, streams ou WebSockets.
Exemplos práticos:
- FastAPI: framework web assíncrono, lida com muitas requisições concorrentes
- Gateways e proxies: abrem muitas conexões ao mesmo tempo
- Crawlers: buscam centenas de URLs em paralelo
- Chat realtime: WebSockets mantendo conexões abertas
- Consumers Kafka/RabbitMQ: processando eventos conforme chegam
Quando não vale?
Nem toda aplicação precisa de async. Às vezes o síncrono é mais simples, mais legível, mais fácil de manter - e suficiente.
Se a aplicação faz poucas operações de I/O, async só adiciona complexidade sem benefício real.
Quadro de decisão
| Situação | Abordagem recomendada |
|---|---|
| Muitas requisições de rede simultâneas | async / await |
| WebSockets, realtime, streams | async / await |
| Poucas operações de I/O | síncrono simples |
| Cálculos pesados de CPU | multiprocessing |
| Bibliotecas que não suportam async | threads (com cuidado) |
| Processamento distribuído em escala | workers + filas (Celery, etc.) |
Conclusão
Quando entendemos I/O, bloqueio, concorrência, corrotinas, Event Loop, cooperatividade, tasks e escalonamento, o async deixa de parecer “mágica” - e passa a fazer sentido arquiteturalmente.
O verdadeiro poder do async está em manter a aplicação trabalhando enquanto outras operações esperam. A diferença entre 58 segundos e 1 segundo para 100 URLs não é magia - é simplesmente o aproveitamento do tempo que antes era desperdiçado esperando.
Mas async não substitui tudo:
- resolve muito bem espera de I/O
- não resolve processamento pesado de CPU - use multiprocessing
- adiciona complexidade - use quando o problema justifica
Entender essa diferença muda completamente a forma como arquitetamos sistemas modernos em Python.
Referências
- asyncio - Asynchronous I/O (documentação oficial do Python)
- Coroutines and Tasks (documentação oficial do Python)
- Streams (documentação oficial do Python)
- Queues (documentação oficial do Python)
- Developing with asyncio (documentação oficial do Python)
- Thread states and the Global Interpreter Lock (documentação oficial do Python)
- PEP 703 - Making the Global Interpreter Lock Optional in CPython
- Requests: HTTP for Humans (documentação oficial)
- HTTPX (documentação oficial)
- aiometer - concurrency scheduling (GitHub)